已经列印出来的文字文件,利用扫描器扫描为图片以后,使用Microsoft Office Office 2003内建的工具「Microsoft Office Document Imaging 」,就可以轻松的辨识图片内的文字〈如果你使用的是Office 2010文字辨识的方法详见:Microsoft OneNote 2010文字辨识〉,这个程式只支援mdi与tif 格式的档案,所以使用扫描器扫描后一定要存成 tif 档案才能被辨识;如果已经储存为其他格式的图片档案,可以使用PhotoCap 6.0等影像处理软体将图片转换为tif档案格式,详见:PhotoCap 6.0批次处理。关于Microsoft Office Document Imaging文字辨识的方法说明如下:
1.开启Windows 7以后,点选「开始\\所有程式」。
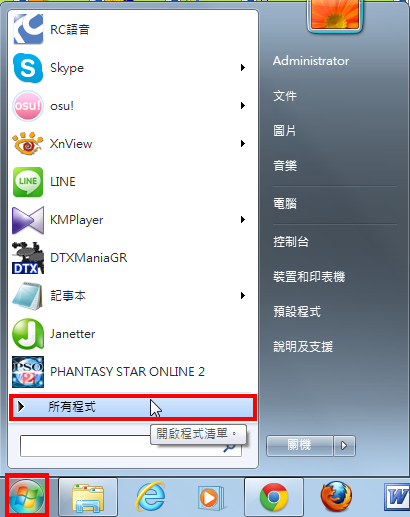
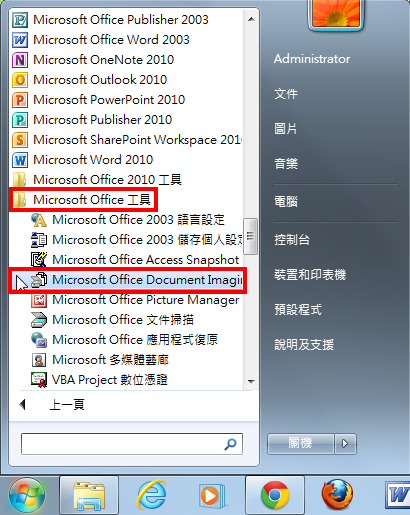
2.点选「Microsoft Office\\Microsoft Office 工具\\ Microsoft Office Document Imaging」。
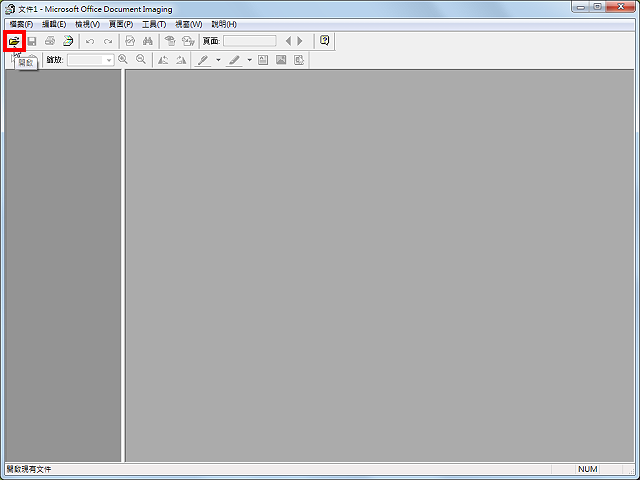
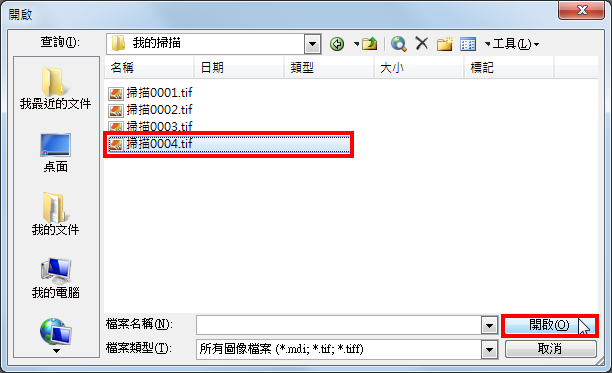
3.开启的Microsoft Office Document Imaging如下图所示,点选「开启」的图示按钮。
4.选择扫描完成的tif格式图片档案,点选「开启」。
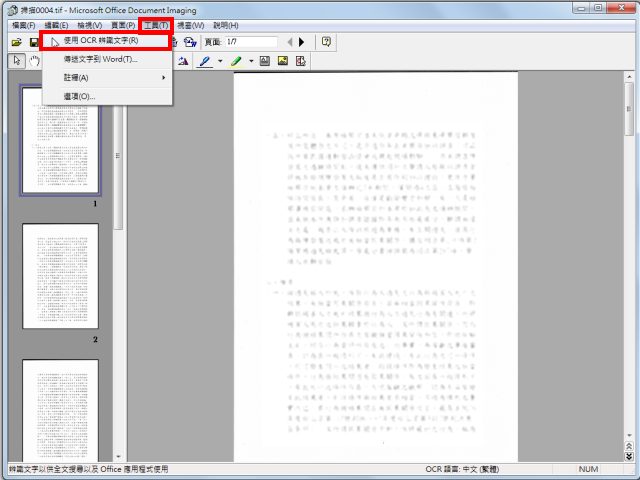
5.点选「工具\\使用OCR辨识文字」。
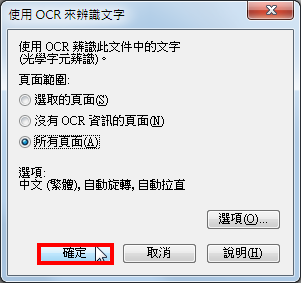
6.使用预设的选项「所有页面」,点选「确定」。
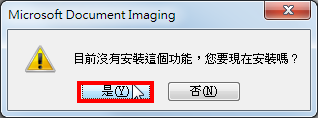
7. Microsoft Office Office 2003内建的「Microsoft Office Document Imaging 」工具预设第一次使用才会安装,点选「是」,进行安装。
8.正在安装程式。
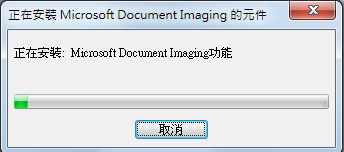
9.程式安装完成,正在辨识文字。
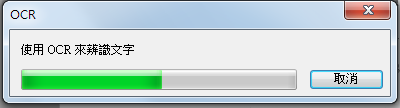
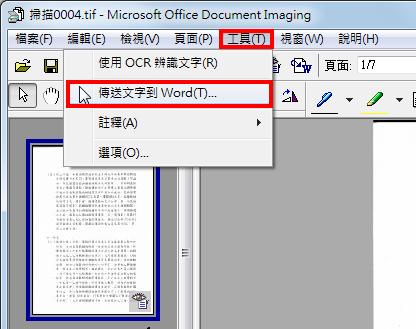
10.文字辨识完成,点选「工具\\传送文字到Word」。
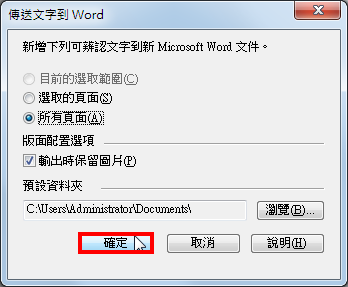
11.使用预设的储存路径,点选「确定」。
12.文字储存成功以后,会自动开启Word 2003,如下图所示,可以开始编辑辨识完成的文章了。
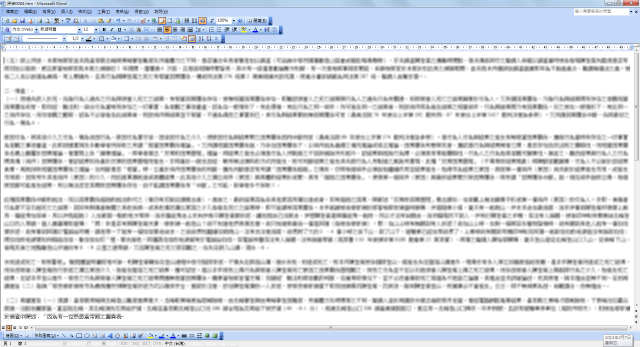
13.关闭「Microsoft Office Document Imaging」,结束文字的辨识。
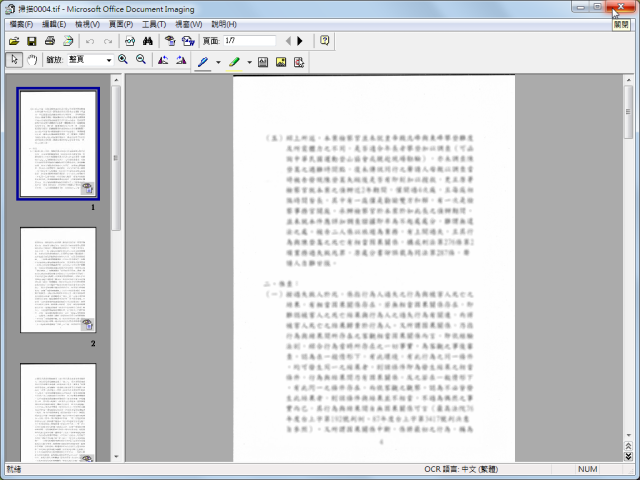
14.因为文字已经辨识完成,点选「否」,不需要储存图片的变更。